Comparer les distributions plutôt que les moyennes : une avancée clé pour le contrôle qualité grâce aux test de Cramée-von Mises et test Energie
Deux lots de pièces. Même moyenne. Même écart-type apparent.
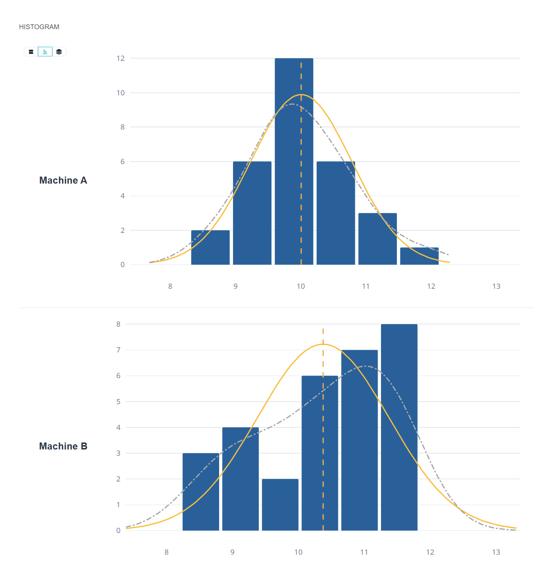
Les moyennes et les variances sont ici sensiblement identiques, et pourtant, intuitivement, on peut sentir une différence entre ces deux machines.
Les tests d’hypothèses classiques ne montrent pourtant aucune différence entre les deux distributions.

Mais la moyenne et la variance ne racontent qu’une partie de l’histoire d’un procédé d’usinage. Pour détecter des différences réelles entre groupes de mesures, entre deux fournisseurs, deux machines, deux équipes, deux périodes de production…il faut comparer les distributions complètes. C’est précisément ce que permettent deux tests statistiques intégrés dans Ellistat Data Analysis : le test de Cramér–von Mises et le test Énergie.
Le test de Cramér–von Mises
Ce test permet de comparer :
- soit un échantillon à une distribution théorique
- soit deux échantillons entre eux
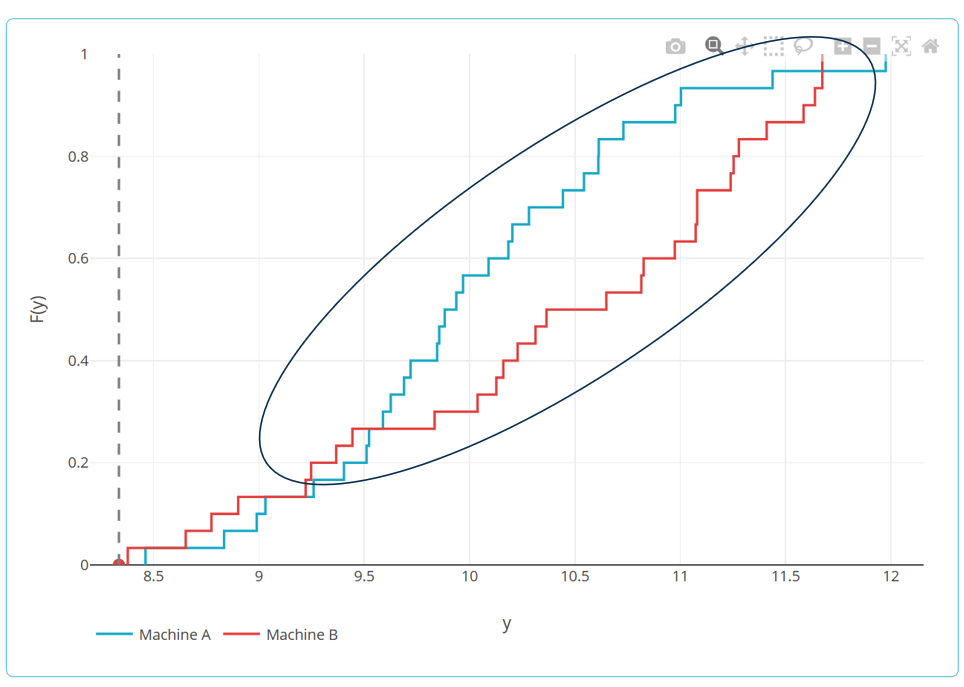
Le principe : le test compare les fonctions de répartitions cumulées (ogives) des deux distributions.
Autrement dit, il mesure « à quel point les courbes cumulées sont éloignées l’une de l’autre » ?
Si les deux distributions sont proches, les ogives se superposent. Si elles diffèrent, l’écart cumulé augmente.
Le test énergie
Ce test généralise cette approche à plusieurs groupes. Il est particulièrement adapté lorsque :
- on compare plus de deux populations
- les distributions sont inconnues
- les données sont multidimentionnelles
Le principe : le test repose sur une idée intuitive : comparer les distances entre les points.
Il mesure :
- les distances moyennes à l’intérieur des groupes
- puis les distances entre groupes
Si les groupes proviennent de la même distribution, les distances intra et inter-groupes sont similaires. Sinon, les distances entre groupes deviennent plus grande.
Ce que ça change en pratique
Comparer deux fournisseurs sur un diamètre critique. Valider un changement de réglage machine. Analyser un avant/après sur un procédé instable. Différencier deux centres d’usinage qui produisent les mêmes pièces…en apparence.
Dans tous ces cas, regarder uniquement la moyenne et la variance peut induire en erreur.
Comparer les distributions complètes donne une image fidèle de ce qui se passe réellement.
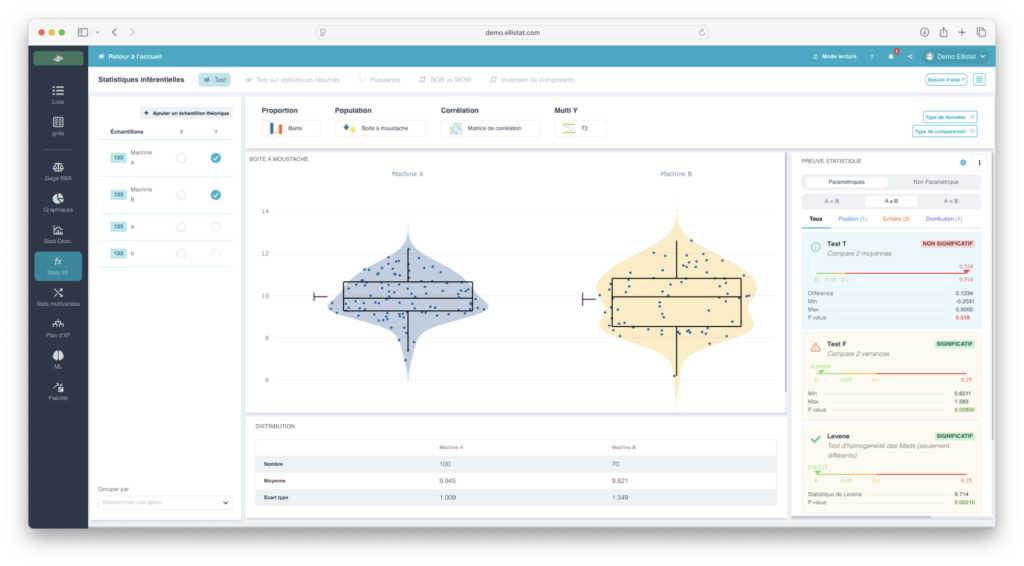
Dans le module Data Analysis d’Ellistat, ces tests sont couplés à des visualisations : ogives, KDE, histogrammes superposés, parce qu’une p-value sans contexte visuel ne convainc personne dans l’atelier.
L’objectif n’est pas de produire un résultat statistique c’est de comprendre pourquoi deux procédés se comportent différemment et d’agir.
