
Per verificare la normalità, esistono diversi test che possono essere utilizzati per convalidare o invalidare l'ipotesi che la distribuzione delle monete segua una distribuzione normale. I test più comunemente utilizzati sono :
- Il test Chi2
- Il test Anderson-Darling
Test di normalità utilizzando il test Chi2
Per verificare la normalità di una distribuzione, la prima intuizione sarebbe quella di tracciare l'istogramma della distribuzione delle variabili osservate. Poi si confronta se questo istogramma assomiglia più o meno all'istogramma della distribuzione delle variabili osservate. Curva di Gauss abituale.
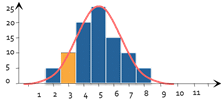
Questo è esattamente il principio alla base del test Chi2. A questa intuizione aggiunge una piccola dose di calcolo statistico. Il principio è il seguente:
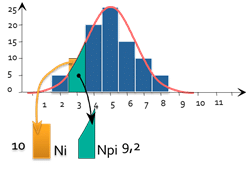
d_i=\frac{(N_i-NP_i)^{2}}{NP_i}
Per ogni barra dell'istogramma, possiamo calcolare :
- Ni : Il numero di parti effettivamente osservate (in questo caso 10)
- Npi: il numero di parti teoricamente osservate se la distribuzione fosse normale (qui 9.2)
- di rappresenta il "numero di pezzi fuori posto".
Calcoliamo quindi
D=somma_{}^{}D_i
e si scopre che D segue una legge di distribuzione con n-2 gradi di libertà (N è il numero di classi). Possiamo quindi calcolare la probabilità di ottenere tale valore.
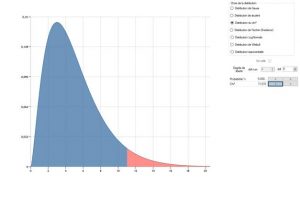
Ad esempio, per un istogramma con 7 classi, se abbiamo calcolato un D di 11,07, calcoliamo che ci sono 5% per ottenere tale valore o più se la distribuzione delle parti è effettivamente normale.
Il risultato del test sarà quindi 5% e la conclusione generale è la seguente:
- Se X < 5%: la distribuzione delle variabili non è considerata una distribuzione normale.
- Se X >= 5%: l'ipotesi di normalità è accettata e la distribuzione può essere considerata normale.
Cosa fare in caso di non normalità
Il teorema del limite centrale ci dice che :
Qualsiasi sistema, risultante dalla somma di molti fattori indipendenti tra loro e di ordine di grandezza equivalente, genera una legge di distribuzione che tende a una distribuzione normale.
Ma possiamo anche ragionare in modo opposto. Se osserviamo una distribuzione che non è normale, allora una delle ipotesi del teorema non è valida:
- Caso 1: il sistema non è la somma di molti fattori: può essere il prodotto di molti fattori o altro. In questo caso, la legge di distribuzione può essere diversa e, in generale, una trasformazione (prendendo il log del risultato, ad esempio) ripristinerà una distribuzione normale.
- Caso 2: I fattori non sono indipendenti l'uno dall'altro
- Caso 3: I fattori non sono dello stesso ordine di grandezza:
- Un fattore prevale sugli altri. In questo caso, dobbiamo trovare il fattore in questione, perché da solo genera una fonte importante di variabilità.
- Un outlier sta inquinando la distribuzione. In questo caso, è necessario trovare la causa dell'outlier ed eliminarlo se la causa può essere spiegata.
In questi due casi, non è necessario trovare una legge di distribuzione corrispondente alla variabilità osservata. Infatti, questa legge di distribuzione non sarà ripetibile nel tempo perché è dovuta a un singolo parametro, quindi non avrà proprietà predittive.
Se l'origine della non normalità è dovuta al caso 1, è necessario trovare la legge di distribuzione corrispondente, soprattutto se si vuole prevedere la percentuale di valori fuori tolleranza. A tale scopo, è possibile utilizzare le leggi di distribuzione suggerite nella parte inferiore della finestra in il modulo Analisi dei dati per vedere se una delle distribuzioni rende conto dei dati osservati: