
Um die Normalverteilung zu testen, gibt es verschiedene Tests, mit denen die Annahme, dass die Verteilung der Münzen einer Normalverteilung folgt, bestätigt oder verworfen werden kann. Die üblicherweise verwendeten Tests sind :
- Der Chi-Quadrat-Test
- Der Anderson-Darling-Test
Normalitätstest mit dem Chi2-Test
Um die Normalverteilung einer Verteilung zu überprüfen, wäre unsere erste Intuition, das Histogramm der Verteilung der beobachteten Variablen zu zeichnen. Dann würden wir vergleichen, ob dieses Histogramm mehr oder weniger der Gauss-Kurve üblich.
Genau das ist das Prinzip des Chi2-Tests. Er fügt dieser Intuition eine kleine Dosis statistischer Berechnung hinzu. Das Prinzip ist wie folgt:
d_i=\frac{(N_i-NP_i)^{2}}{NP_i}
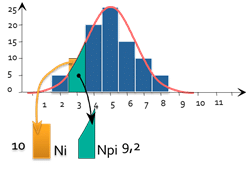
Für jeden Balken im Histogramm kann man berechnen :
- Ni: Die Anzahl der tatsächlich beobachteten Räume (hier 10)
- Npi: Die Anzahl der Stücke, die theoretisch beobachtet würde, wenn die Verteilung normal wäre (hier 9.2).
- di steht für die "Anzahl der falsch geordneten Teile".
Anschließend berechnet man
D \cum_{}^{}D_i
und es stellt sich heraus, dass D einer Verteilungsregel der du mit n-2 Freiheitsgraden folgt (N ist die Anzahl der Klassen). Infolgedessen können wir die Wahrscheinlichkeit berechnen, dass wir einen solchen Wert erhalten.
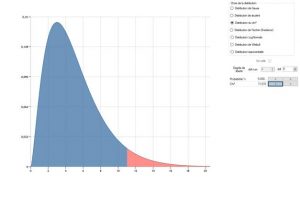
Wenn wir zum Beispiel für ein Histogramm mit 7 Klassen einen D-Wert von 11,07 berechnet haben, berechnen wir, dass es 5% gibt, einen solchen Wert oder mehr zu erreichen, wenn die Verteilung der Teile tatsächlich normalverteilt ist.
Das Testergebnis lautet also 5% und man schließt in der Regel wie folgt:
- Wenn X < 5%: Es wird nicht davon ausgegangen, dass die Verteilung der Variablen einer Normalverteilung folgt.
- Wenn X >= 5%: Die Normalitätsannahme wird akzeptiert, es kann davon ausgegangen werden, dass die Verteilung einer Normalverteilung folgt.
Was tun, wenn es nicht normal ist
Der zentrale Grenzwertsatz sagt uns :
Jedes System, das sich aus der Summe vieler voneinander unabhängiger Faktoren gleicher Größenordnung ergibt, erzeugt eine Verteilungsregel, die zu einer Normalverteilung tendiert.
Man kann aber auch umgekehrt argumentieren. Wenn wir eine Gesetzmäßigkeit beobachten, die nicht normal ist, dann ist eine der Annahmen des Theorems ungültig:
- Fall 1: Das System ist nicht das Ergebnis der Summe vieler Faktoren: Es ist vielleicht das Produkt vieler Faktoren oder etwas anderes. In diesem Fall kann das Verteilungsgesetz unterschiedlich sein und in der Regel wird durch eine Transformation (z. B. indem man den Log des Ergebnisses nimmt) wieder eine Normalverteilung erreicht.
- Fall 2: Die Faktoren sind nicht unabhängig voneinander
- Fall 3: Die Faktoren sind nicht von gleicher Größenordnung :
- Ein Faktor ist vor allen anderen Faktoren vorherrschend. In diesem Fall gilt es, diesen Faktor zu finden, da er allein eine bedeutende Quelle der Variabilität erzeugt.
- Ein Ausreißer verschmutzt die Verteilung. In diesem Fall sollte die Ursache für den Ausreißer gefunden und der Wert beseitigt werden, wenn die Ursache erklärt werden konnte.
In beiden Fällen ist es nicht sinnvoll, ein Verteilungsgesetz zu finden, das der beobachteten Variabilität entspricht. Denn dieses Verteilungsgesetz wird im Laufe der Zeit nicht wiederholbar sein, da es auf einen einzigen Parameter zurückzuführen ist, es hat also keine prädiktive Eigenschaft.
Wenn der Ursprung der Nichtnormalität auf Fall 1 zurückzuführen ist, müssen Sie von nun an das entsprechende Verteilungsgesetz finden, insbesondere wenn Sie den Prozentsatz der Werte außerhalb der Toleranz vorhersagen möchten. Dazu können Sie die Vorschläge für Verteilungsgesetze am unteren Rand des Fensters in das Modul Data Analysis um zu sehen, ob eine der Verteilungen die beobachteten Daten wiedergeben kann :